使用 AI 实现音乐源分离
作者参考:Sean Kim
模型来源:Hybrid Demucs(Défossez, 2021)
一、项目简介
本教程介绍如何借助 Hybrid Demucs 模型完成音乐源分离(Music Source Separation)任务,即从一段完整音乐中拆分出:
- 人声(Vocals)
- 鼓点(Drums)
- 贝斯(Bass)
- 其它伴奏(Other)
整个流程主要包含以下几个阶段:
- 初始化 Hybrid Demucs 分离模型
- 将长音频切分为多个带重叠区域的小片段
- 分块执行模型推理
- 对所有片段进行融合恢复
- 输出不同音轨并进行频谱分析
Hybrid Demucs 是经典 Demucs 模型的增强版本。
它结合:
- 时域卷积(Waveform-based)
- 频域特征学习(Spectrogram-based)
因此相比传统方案能够得到更加自然的分离效果。
相关论文:
- Hybrid Demucs: https://arxiv.org/abs/2111.03600
- 官方项目: https://github.com/facebookresearch/demucs
二、环境准备
首先安装运行所需依赖:
pip install torch torchaudio matplotlib随后导入必要模块:
import torch
import torchaudio
import matplotlib.pyplot as plt
from IPython.display import Audio
from torchaudio.pipelines import HDEMUCS_HIGH_MUSDB_PLUS
from torchaudio.utils import _download_asset查看当前版本:
print(torch.__version__)
print(torchaudio.__version__)三、加载 Hybrid Demucs 模型
Torchaudio 已经封装好了预训练模型:
bundle = HDEMUCS_HIGH_MUSDB_PLUS
model = bundle.get_model()这里使用的模型:
- 基于 MUSDB18-HQ 数据集训练
- 额外加入内部扩展数据
- 适用于 44.1kHz 高质量音频
模型参数:
- FFT Size:4096
- 网络深度:6
设置运行设备:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
sample_rate = bundle.sample_rate
print(f"Sample rate: {sample_rate}")四、构建音频分离函数
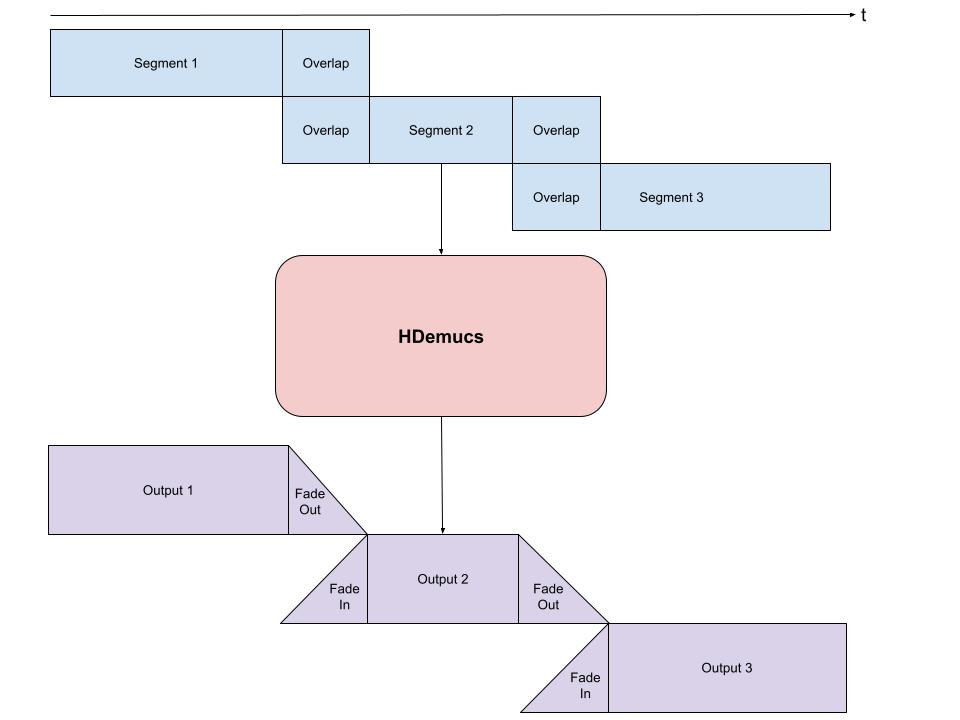
由于 HDemucs 模型占用显存较大,因此无法直接对整首歌曲进行一次性推理。
通常采用:
- 分段切块(Chunk)
- 重叠拼接(Overlap)
- Fade 淡入淡出
的方式完成长音频处理。
这样做的原因是:
- 模型在片段边缘容易产生伪影(Artifacts)
- 使用重叠区域可以降低边界噪声
如下图所示:
4.1 分离函数实现
from torchaudio.transforms import Fade
def separate_sources(
model,
mix,
segment=10.0,
overlap=0.1,
device=None,
):
"""
使用分块方式完成音源分离
Args:
segment: 每段音频长度(秒)
overlap: 重叠比例
device: 推理设备
"""
if device is None:
device = mix.device
else:
device = torch.device(device)
batch, channels, length = mix.shape
chunk_len = int(sample_rate * segment * (1 + overlap))
start = 0
end = chunk_len
overlap_frames = overlap * sample_rate
fade = Fade(
fade_in_len=0,
fade_out_len=int(overlap_frames),
fade_shape="linear",
)
final = torch.zeros(
batch,
len(model.sources),
channels,
length,
device=device,
)
while start < length - overlap_frames:
chunk = mix[:, :, start:end]
with torch.no_grad():
out = model.forward(chunk)
out = fade(out)
final[:, :, :, start:end] += out
if start == 0:
fade.fade_in_len = int(overlap_frames)
start += int(chunk_len - overlap_frames)
else:
start += chunk_len
end += chunk_len
if end >= length:
fade.fade_out_len = 0
return final五、绘制频谱图
定义一个简单的频谱可视化函数:
def plot_spectrogram(stft, title="Spectrogram"):
magnitude = stft.abs()
spectrogram = 20 * torch.log10(
magnitude + 1e-8
).numpy()
_, axis = plt.subplots(1, 1)
axis.imshow(
spectrogram,
cmap="viridis",
vmin=-60,
vmax=0,
origin="lower",
aspect="auto",
)
axis.set_title(title)
plt.tight_layout()六、运行模型进行分离
这里使用官方提供的示例音频:
SAMPLE_SONG = _download_asset(
"tutorial-assets/hdemucs_mix.wav"
)
waveform, sample_rate = torchaudio.load(SAMPLE_SONG)
waveform = waveform.to(device)
mixture = waveform设置参数:
segment = 10
overlap = 0.1归一化处理:
ref = waveform.mean(0)
waveform = (
waveform - ref.mean()
) / ref.std()执行分离:
sources = separate_sources(
model,
waveform[None],
device=device,
segment=segment,
overlap=overlap,
)[0]
sources = sources * ref.std() + ref.mean()保存结果:
sources_list = model.sources
sources = list(sources)
audios = dict(zip(sources_list, sources))七、模型输出结果
模型默认输出 4 个轨道:
| 音轨 | 说明 |
|---|---|
| drums | 鼓声 |
| bass | 贝斯 |
| vocals | 人声 |
| other | 其它伴奏 |
八、频谱分析
设置 STFT 参数:
N_FFT = 4096
N_HOP = 4
stft = torchaudio.transforms.Spectrogram(
n_fft=N_FFT,
hop_length=N_HOP,
power=None,
)九、音频片段裁剪
截取 150s ~ 155s 音频区间:
segment_start = 150
segment_end = 155
frame_start = segment_start * sample_rate
frame_end = segment_end * sample_rate加载参考音轨:
drums_original = _download_asset(
"tutorial-assets/hdemucs_drums_segment.wav"
)
bass_original = _download_asset(
"tutorial-assets/hdemucs_bass_segment.wav"
)
vocals_original = _download_asset(
"tutorial-assets/hdemucs_vocals_segment.wav"
)
other_original = _download_asset(
"tutorial-assets/hdemucs_other_segment.wav"
)提取预测结果:
drums_spec = audios["drums"][:, frame_start:frame_end].cpu()
bass_spec = audios["bass"][:, frame_start:frame_end].cpu()
vocals_spec = audios["vocals"][:, frame_start:frame_end].cpu()
other_spec = audios["other"][:, frame_start:frame_end].cpu()
mix_spec = mixture[:, frame_start:frame_end].cpu()十、输出频谱与音频
定义结果展示函数:
def output_results(
original_source: torch.Tensor,
predicted_source: torch.Tensor,
source: str,
):
plot_spectrogram(
stft(predicted_source)[0],
f"Spectrogram - {source}"
)
return Audio(
predicted_source,
rate=sample_rate
)十一、混合音频频谱
plot_spectrogram(
stft(mix_spec)[0],
"Spectrogram - Mixture"
)
Audio(mix_spec, rate=sample_rate)十二、鼓声分离结果
output_results(
drums,
drums_spec,
"drums"
)十三、贝斯分离结果
output_results(
bass,
bass_spec,
"bass"
)十四、人声分离结果
output_results(
vocals,
vocals_spec,
"vocals"
)十五、其它伴奏分离结果
output_results(
other,
other_spec,
"other"
)十六、完整音频试听
如需试听完整分离结果,可取消下列代码注释:
# 原始混音
# Audio(mixture, rate=sample_rate)
# 鼓声
# Audio(audios["drums"], rate=sample_rate)
# 贝斯
# Audio(audios["bass"], rate=sample_rate)
# 人声
# Audio(audios["vocals"], rate=sample_rate)
# 其它伴奏
# Audio(audios["other"], rate=sample_rate)十七、总结
Hybrid Demucs 结合:
- 时域卷积网络
- 频域频谱学习
相比传统音源分离方法:
- 分离质量更高
- 人声更加干净
- 伴奏泄漏更少
同时,本教程采用:
- Chunk 分段
- Overlap 重叠
- Fade 淡入淡出
的工程化方式解决长音频推理问题,非常适合实际项目部署。
适用方向包括:
- AI 翻唱
- 人声提取
- 卡拉 OK
- 音乐重混
- 自动编曲
- 音频后处理
参考文献(References)
下面列出了 Hybrid Demucs、音乐源分离以及相关深度学习音频处理领域的重要参考资料。
一、Hybrid Demucs 相关论文
[1] Hybrid Spectrogram and Waveform Source Separation
作者:Alexandre Défossez
会议/期刊:Proceedings of the ISMIR 2021 Workshop
年份:2021
Défossez, A. (2021).
Hybrid Spectrogram and Waveform Source Separation.
arXiv preprint arXiv:2111.03600.论文地址:
https://arxiv.org/abs/2111.03600
该论文提出了 Hybrid Demucs 架构,将:
- 波形域卷积
- 频谱域学习
进行融合,是当前高质量音乐分离的重要模型之一。
[2] Music Source Separation in the Waveform Domain
作者:Alexandre Défossez, Nicolas Usunier, Léon Bottou, Francis Bach
会议:ISMIR 2019
年份:2019
Défossez, A., Usunier, N., Bottou, L., & Bach, F. (2019).
Music Source Separation in the Waveform Domain.
Proceedings of the 20th International Society for Music Information Retrieval Conference (ISMIR).论文地址:
https://arxiv.org/abs/1911.13254
这是 Demucs 的原始论文,首次提出完全基于波形的音乐分离方案。
二、数据集相关文献
[3] The MUSDB18 Corpus for Music Separation
作者:Zafar Rafii 等
数据集:MUSDB18-HQ
年份:2017
Rafii, Z., Liutkus, A., Stöter, F.-R., Mimilakis, S. I.,
Bittner, R., & Pardo, B. (2017).
The MUSDB18 Corpus for Music Separation.数据集地址:
https://zenodo.org/record/3338373
MUSDB18-HQ 是当前音乐源分离领域最常用的标准数据集之一。
三、PyTorch / Torchaudio 官方资料
[4] Torchaudio Official Documentation
PyTorch Audio Team.
Torchaudio Documentation.官方文档:
https://pytorch.org/audio/stable/index.html
[5] Hybrid Demucs Tutorial (Official)
PyTorch Audio Team.
Music Source Separation with Hybrid Demucs.教程地址:
https://docs.pytorch.org/audio/stable/tutorials/hybrid_demucs_tutorial.html
本文实验流程与代码结构参考了官方教程实现。
四、音乐源分离经典研究
[6] Open-Unmix — A Reference Implementation for Music Source Separation
作者:Fabian-Robert Stöter 等
会议:Journal of Open Source Software
年份:2019
Stöter, F.-R., Liutkus, A., & Ito, N. (2019).
The 2018 Signal Separation Evaluation Campaign.
Journal of Open Source Software.论文地址:
https://sigsep.github.io/open-unmix/
[7] Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation
作者:Andreas Jansson 等
会议:ISMIR 2017
Jansson, A., Humphrey, E., Montecchio, N.,
Bittner, R., Kumar, A., & Weyde, T. (2017).
Singing Voice Separation with Deep U-Net Convolutional Networks.论文地址:
https://ismir2017.smcnus.org/wp-content/uploads/2017/10/171_Paper.pdf
五、评价指标相关文献
[8] BSS Eval Metrics
Vincent, E., Gribonval, R., & Févotte, C. (2006).
Performance Measurement in Blind Audio Source Separation.
IEEE Transactions on Audio, Speech, and Language Processing.论文地址:
https://ieeexplore.ieee.org/document/1643671
该论文提出了:
- SDR
- SIR
- SAR
等经典音频分离评价指标。
六、深度学习音频处理相关教材
[9] Deep Learning for Audio Signal Processing
Kellman, M., et al.
Deep Learning for Audio Signal Processing.出版机构:
Cambridge University Press
[10] Fundamentals of Music Processing
Müller, M. (2015).
Fundamentals of Music Processing.
Springer.图书地址:
https://www.music-processing.de/
七、推荐进一步阅读
下面这些资源非常适合进一步深入学习:
| 主题 | 资源 |
|---|---|
| Demucs 官方项目 | https://github.com/facebookresearch/demucs |
| PyTorch Audio | https://pytorch.org/audio/stable/index.html |
| Source Separation 社区 | https://sigsep.github.io/ |
| MUSDB 数据集 | https://zenodo.org/record/3338373 |
| ISMIR 学会 | https://ismir.net/ |