Music Source Separation With AI
Author Reference: Sean Kim
Model Reference: Hybrid Demucs (Défossez, 2021)
1. Introduction
This tutorial demonstrates how to perform music source separation using the Hybrid Demucs model. The objective is to decompose a mixed music track into its constituent stems, including:
- Vocals
- Drums
- Bass
- Other accompaniment components
The complete workflow consists of the following stages:
- Initializing the Hybrid Demucs separation model
- Splitting long audio into overlapping chunks
- Running chunk-wise model inference
- Reconstructing the full-length audio from all segments
- Exporting separated stems and visualizing spectrograms
Hybrid Demucs is an enhanced version of the original Demucs architecture.
It combines:
- Waveform-domain convolutional modeling
- Spectrogram-domain feature learning
By jointly leveraging time-domain and frequency-domain representations, Hybrid Demucs achieves significantly more natural and higher-fidelity source separation compared to conventional approaches.
Related resources:
- Hybrid Demucs paper: https://arxiv.org/abs/2111.03600
- Official repository: https://github.com/facebookresearch/demucs
2. Environment Setup
Install the required dependencies:
pip install torch torchaudio matplotlibImport the necessary modules:
import torch
import torchaudio
import matplotlib.pyplot as plt
from IPython.display import Audio
from torchaudio.pipelines import HDEMUCS_HIGH_MUSDB_PLUS
from torchaudio.utils import _download_assetCheck the installed versions:
print(torch.__version__)
print(torchaudio.__version__)3. Loading the Hybrid Demucs Model
Torchaudio provides a pre-trained Hybrid Demucs pipeline out of the box:
bundle = HDEMUCS_HIGH_MUSDB_PLUS
model = bundle.get_model()The selected model:
- Is trained on the MUSDB18-HQ dataset
- Includes additional proprietary augmentation data
- Is optimized for high-quality 44.1kHz audio processing
Model configuration:
- FFT Size: 4096
- Network Depth: 6
Configure the execution device:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
sample_rate = bundle.sample_rate
print(f"Sample rate: {sample_rate}")4. Building the Audio Separation Pipeline
Because HDemucs is computationally intensive and memory-demanding, performing inference on an entire song in a single pass is often impractical.
In real-world deployments, long audio is typically processed using:
- Chunk-based segmentation
- Overlapping windows
- Fade-in / fade-out smoothing
This strategy is necessary because:
- Neural models tend to generate artifacts near segment boundaries
- Overlapping regions help reduce discontinuities and boundary noise
The processing strategy is illustrated below:
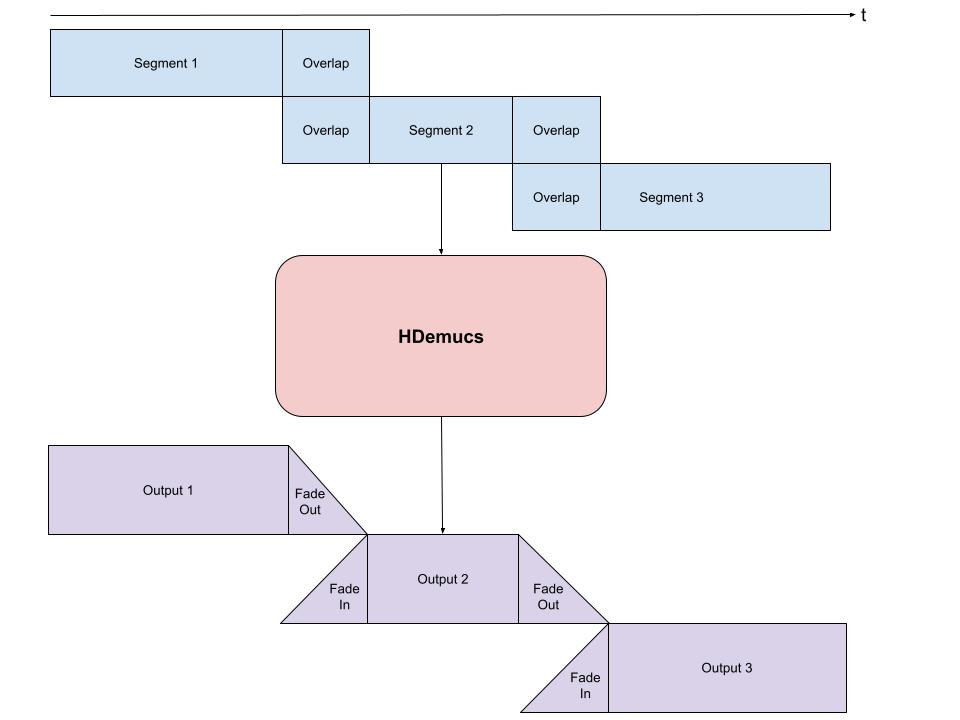
4.1 Implementing the Separation Function
from torchaudio.transforms import Fade
def separate_sources(
model,
mix,
segment=10.0,
overlap=0.1,
device=None,
):
"""
Perform music source separation using chunked inference.
Args:
segment: Length of each audio chunk in seconds
overlap: Overlap ratio between consecutive chunks
device: Inference device
"""
if device is None:
device = mix.device
else:
device = torch.device(device)
batch, channels, length = mix.shape
chunk_len = int(sample_rate * segment * (1 + overlap))
start = 0
end = chunk_len
overlap_frames = overlap * sample_rate
fade = Fade(
fade_in_len=0,
fade_out_len=int(overlap_frames),
fade_shape="linear",
)
final = torch.zeros(
batch,
len(model.sources),
channels,
length,
device=device,
)
while start < length - overlap_frames:
chunk = mix[:, :, start:end]
with torch.no_grad():
out = model.forward(chunk)
out = fade(out)
final[:, :, :, start:end] += out
if start == 0:
fade.fade_in_len = int(overlap_frames)
start += int(chunk_len - overlap_frames)
else:
start += chunk_len
end += chunk_len
if end >= length:
fade.fade_out_len = 0
return final5. Spectrogram Visualization
Define a helper function for spectrogram visualization:
def plot_spectrogram(stft, title="Spectrogram"):
magnitude = stft.abs()
spectrogram = 20 * torch.log10(
magnitude + 1e-8
).numpy()
_, axis = plt.subplots(1, 1)
axis.imshow(
spectrogram,
cmap="viridis",
vmin=-60,
vmax=0,
origin="lower",
aspect="auto",
)
axis.set_title(title)
plt.tight_layout()6. Running Source Separation
Use the official demonstration audio provided by Torchaudio:
SAMPLE_SONG = _download_asset(
"tutorial-assets/hdemucs_mix.wav"
)
waveform, sample_rate = torchaudio.load(SAMPLE_SONG)
waveform = waveform.to(device)
mixture = waveformConfigure inference parameters:
segment = 10
overlap = 0.1Normalize the waveform:
ref = waveform.mean(0)
waveform = (
waveform - ref.mean()
) / ref.std()Run source separation:
sources = separate_sources(
model,
waveform[None],
device=device,
segment=segment,
overlap=overlap,
)[0]
sources = sources * ref.std() + ref.mean()Store the separated stems:
sources_list = model.sources
sources = list(sources)
audios = dict(zip(sources_list, sources))7. Model Outputs
The default Hybrid Demucs model produces four stems:
| Stem | Description |
|---|---|
| drums | Percussion and drum tracks |
| bass | Bass instruments |
| vocals | Lead and backing vocals |
| other | Remaining accompaniment |
8. Spectrogram Analysis
Configure STFT parameters:
N_FFT = 4096
N_HOP = 4
stft = torchaudio.transforms.Spectrogram(
n_fft=N_FFT,
hop_length=N_HOP,
power=None,
)9. Audio Segment Extraction
Extract the segment between 150s and 155s:
segment_start = 150
segment_end = 155
frame_start = segment_start * sample_rate
frame_end = segment_end * sample_rateLoad the corresponding reference stems:
drums_original = _download_asset(
"tutorial-assets/hdemucs_drums_segment.wav"
)
bass_original = _download_asset(
"tutorial-assets/hdemucs_bass_segment.wav"
)
vocals_original = _download_asset(
"tutorial-assets/hdemucs_vocals_segment.wav"
)
other_original = _download_asset(
"tutorial-assets/hdemucs_other_segment.wav"
)Extract predicted segments:
drums_spec = audios["drums"][:, frame_start:frame_end].cpu()
bass_spec = audios["bass"][:, frame_start:frame_end].cpu()
vocals_spec = audios["vocals"][:, frame_start:frame_end].cpu()
other_spec = audios["other"][:, frame_start:frame_end].cpu()
mix_spec = mixture[:, frame_start:frame_end].cpu()10. Rendering Spectrograms and Audio
Define a utility function for visualization and playback:
def output_results(
original_source: torch.Tensor,
predicted_source: torch.Tensor,
source: str,
):
plot_spectrogram(
stft(predicted_source)[0],
f"Spectrogram - {source}"
)
return Audio(
predicted_source,
rate=sample_rate
)11. Mixture Spectrogram
plot_spectrogram(
stft(mix_spec)[0],
"Spectrogram - Mixture"
)
Audio(mix_spec, rate=sample_rate)12. Drum Separation Results
output_results(
drums,
drums_spec,
"drums"
)13. Bass Separation Results
output_results(
bass,
bass_spec,
"bass"
)14. Vocal Separation Results
output_results(
vocals,
vocals_spec,
"vocals"
)15. Other Accompaniment Results
output_results(
other,
other_spec,
"other"
)16. Full-Length Audio Playback
To listen to the complete separated stems, uncomment the following code:
# Original mixture
# Audio(mixture, rate=sample_rate)
# Drums
# Audio(audios["drums"], rate=sample_rate)
# Bass
# Audio(audios["bass"], rate=sample_rate)
# Vocals
# Audio(audios["vocals"], rate=sample_rate)
# Other accompaniment
# Audio(audios["other"], rate=sample_rate)17. Conclusion
Hybrid Demucs integrates:
- Time-domain convolutional modeling
- Frequency-domain spectrogram learning
Compared with traditional source separation approaches, it offers:
- Higher separation fidelity
- Cleaner vocal isolation
- Reduced accompaniment leakage
This tutorial additionally adopts practical engineering strategies including:
- Chunk-based inference
- Overlap reconstruction
- Fade smoothing
These techniques effectively address long-audio inference challenges and are highly suitable for real-world deployment scenarios.
Typical applications include:
- AI singing voice conversion
- Vocal extraction
- Karaoke generation
- Music remixing
- Automatic arrangement
- Audio post-processing
References
The following references cover Hybrid Demucs, music source separation, and deep learning-based audio processing.
1. Hybrid Demucs
[1] Hybrid Spectrogram and Waveform Source Separation
Author: Alexandre Défossez
Venue: ISMIR 2021 Workshop
Year: 2021
Défossez, A. (2021).
Hybrid Spectrogram and Waveform Source Separation.
arXiv preprint arXiv:2111.03600.Paper:
https://arxiv.org/abs/2111.03600
This work introduced the Hybrid Demucs architecture, which combines:
- Waveform-domain convolution
- Spectrogram-domain representation learning
It remains one of the most influential architectures in modern music source separation.
[2] Music Source Separation in the Waveform Domain
Authors: Alexandre Défossez, Nicolas Usunier, Léon Bottou, Francis Bach
Conference: ISMIR 2019
Year: 2019
Défossez, A., Usunier, N., Bottou, L., & Bach, F. (2019).
Music Source Separation in the Waveform Domain.
Proceedings of the 20th International Society for Music Information Retrieval Conference (ISMIR).Paper:
https://arxiv.org/abs/1911.13254
This paper introduced the original Demucs architecture and pioneered waveform-based end-to-end music source separation.
2. Dataset References
[3] The MUSDB18 Corpus for Music Separation
Authors: Zafar Rafii et al.
Dataset: MUSDB18-HQ
Year: 2017
Rafii, Z., Liutkus, A., Stöter, F.-R., Mimilakis, S. I.,
Bittner, R., & Pardo, B. (2017).
The MUSDB18 Corpus for Music Separation.Dataset:
https://zenodo.org/record/3338373
MUSDB18-HQ is one of the most widely adopted benchmark datasets for music source separation research.
3. PyTorch / Torchaudio Documentation
[4] Torchaudio Official Documentation
PyTorch Audio Team.
Torchaudio Documentation.Documentation:
https://pytorch.org/audio/stable/index.html
[5] Official Hybrid Demucs Tutorial
PyTorch Audio Team.
Music Source Separation with Hybrid Demucs.Tutorial:
https://docs.pytorch.org/audio/stable/tutorials/hybrid_demucs_tutorial.html
The implementation structure and experimental workflow presented in this article are partially inspired by the official tutorial.
4. Classical Research in Music Source Separation
[6] Open-Unmix — A Reference Implementation for Music Source Separation
Authors: Fabian-Robert Stöter et al.
Journal: Journal of Open Source Software
Year: 2019
Stöter, F.-R., Liutkus, A., & Ito, N. (2019).
The 2018 Signal Separation Evaluation Campaign.
Journal of Open Source Software.Project:
https://sigsep.github.io/open-unmix/
[7] Wave-U-Net: A Multi-Scale Neural Network for End-to-End Audio Source Separation
Authors: Andreas Jansson et al.
Conference: ISMIR 2017
Jansson, A., Humphrey, E., Montecchio, N.,
Bittner, R., Kumar, A., & Weyde, T. (2017).
Singing Voice Separation with Deep U-Net Convolutional Networks.Paper:
https://ismir2017.smcnus.org/wp-content/uploads/2017/10/171_Paper.pdf
5. Evaluation Metrics
[8] BSS Eval Metrics
Vincent, E., Gribonval, R., & Févotte, C. (2006).
Performance Measurement in Blind Audio Source Separation.
IEEE Transactions on Audio, Speech, and Language Processing.Paper:
https://ieeexplore.ieee.org/document/1643671
This work introduced several classical evaluation metrics for source separation, including:
- SDR (Signal-to-Distortion Ratio)
- SIR (Signal-to-Interference Ratio)
- SAR (Signal-to-Artifacts Ratio)
6. Deep Learning for Audio Processing
[9] Deep Learning for Audio Signal Processing
Kellman, M., et al.
Deep Learning for Audio Signal Processing.Publisher:
Cambridge University Press
[10] Fundamentals of Music Processing
Müller, M. (2015).
Fundamentals of Music Processing.
Springer.Book website:
https://www.music-processing.de/
7. Recommended Resources for Further Study
| Topic | Resource |
|---|---|
| Demucs Official Repository | https://github.com/facebookresearch/demucs |
| PyTorch Audio | https://pytorch.org/audio/stable/index.html |
| Source Separation Community | https://sigsep.github.io/ |
| MUSDB Dataset | https://zenodo.org/record/3338373 |
| ISMIR Society | https://ismir.net/ |